const START_TAG_REG = /^<([^<>\s\/]+)((\s+[^=>\s]+(\s*=\s*((\"[^"]*\")|(\'[^']*\')|[^>\s]+))?)*)\s*\/?\s*>/m
const END_TAG_REG = /^<\/([^>\s]+)[^>]*>/m
const ATTRIBUTE_REG = /([^=\s]+)(\s*=\s*((\"([^"]*)\")|(\'([^']*)\')|[^>\s]+))?/gm
export class ASTElement {
type
children
tag
text
data
parent
constructor(
type: 'Element' | 'Text' | 'Comment',
children: ASTElement[],
tag: string,
text: string,
data: ASTElementData | null,
parent: ASTElement | ASTRoot
) {
this.type = type
this.children = children
this.tag = tag
this.text = text
this.data = data
this.parent = parent
}
}
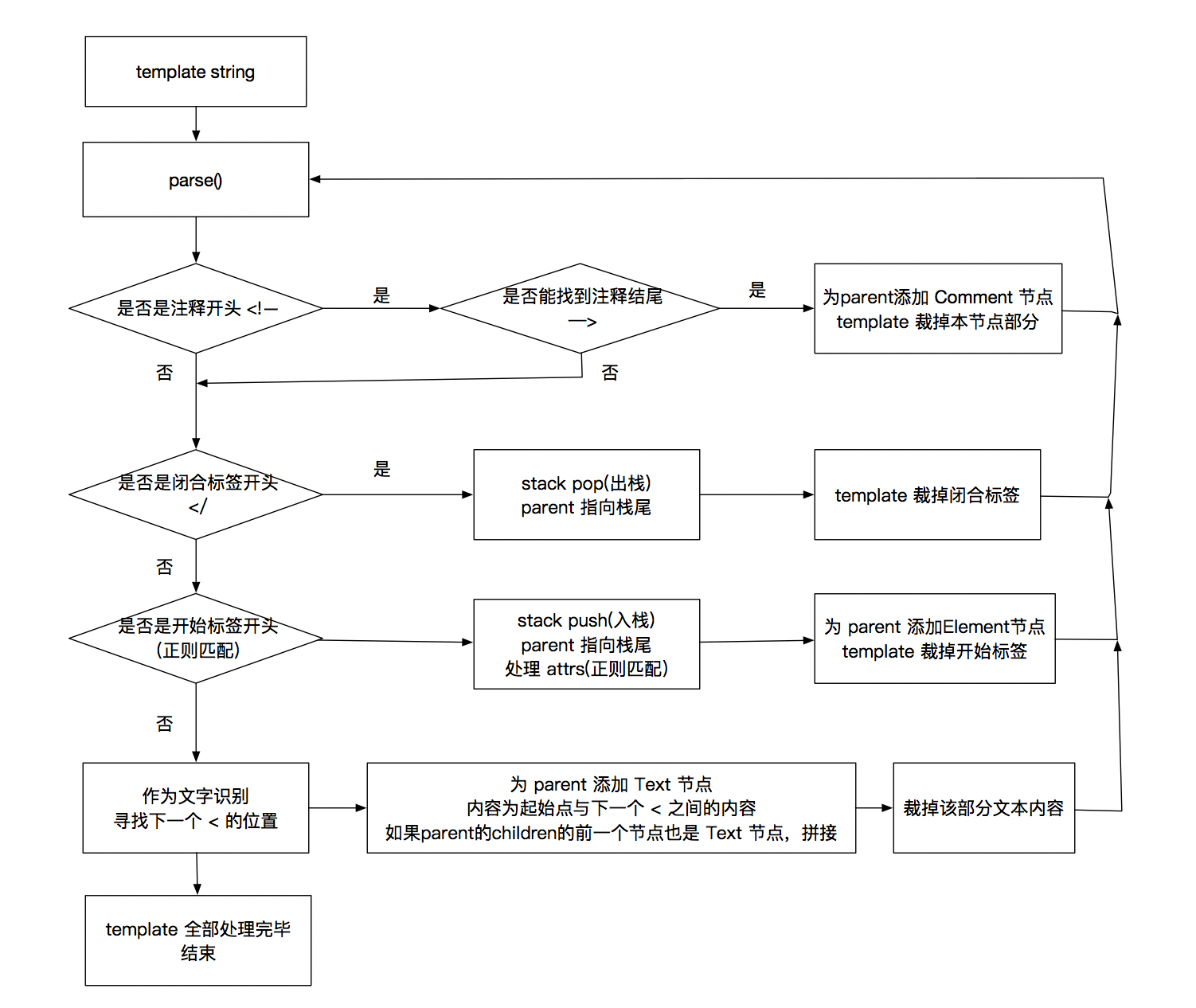
export default function parse(source: string): ASTElement[] {
let result = {
children: []
}
let stack = []
let parent: any = null
stack.push(result)
parent = result
while(source.length > 0) {
if(source.startsWith('<!--')) {
let endIndex = source.indexOf('-->')
if(endIndex !== -1) {
parent.children.push(new ASTElement('Comment', [], '', source.substring(4, endIndex), {}, parent))
source = source.substring(endIndex + 3)
continue
}
}
else if(source.startsWith('</') && END_TAG_REG.test(source)) {
let left = RegExp.leftContext
let tag = RegExp.lastMatch
let right = RegExp.rightContext
let result = tag.match(END_TAG_REG)
let name = result[1]
if(name === parent.tag) {
stack.pop()
parent = stack[stack.length - 1]
}else {
throw new Error('闭合标签对不上,html 语法出错')
}
source = right
continue
}
else if(source.charAt(0) === '<' && START_TAG_REG.test(source)) {
let left = RegExp.leftContext
let tag = RegExp.lastMatch
let right = RegExp.rightContext
let result = tag.match(START_TAG_REG)
let tagName = result[1]
let attrs = result[2]
let attrMap = {}
let nodeData: ASTElementData = {
attrs: {},
events: {},
directives: {},
rawAttrs: {}
}
if(attrs) {
attrs.replace(ATTRIBUTE_REG, (a0, a1, a2, a3, a4, a5, a6) => {
let attrName = a1
let attrValue = a3 || null
if(attrValue && attrValue.startsWith('"') && attrValue.endsWith('"')) {
attrMap[attrName] = attrValue.slice(1, attrValue.length - 1)
}else if(attrValue && attrValue.startsWith("'") && attrValue.endsWith("'")) {
attrMap[attrName] = attrValue.slice(1, attrValue.length - 1)
}else {
attrMap[attrName] = attrValue
}
return ''
})
}
processAttrs(nodeData, attrMap)
let element = new ASTElement('Element', [], tagName, '', nodeData, parent)
parent.children.push(element)
if(!tag.endsWith('/>')) {
stack.push(element)
parent = element
}
source = right
continue
}
let index = source.indexOf('<', 1)
if(index == -1) {
if(parent.children[parent.children.length - 1] && parent.children[parent.children.length - 1].type === 'Text') {
parent.children[parent.children.length - 1].text += source
}else {
parent.children.push(new ASTElement('Text', [], '', source, {}, parent))
}
source = ''
}else {
if(parent.children[parent.children.length - 1] && parent.children[parent.children.length - 1].type === 'Text') {
parent.children[parent.children.length - 1].text += source.substring(0, index)
}else {
parent.children.push(new ASTElement('Text', [], '', source.substring(0, index), {}, parent))
}
source = source.substring(index)
}
}
return result.children
}
function processAttrs(nodeData, attrMap) {
Object.keys(attrMap).forEach(k => {
if(k === ':key') {
nodeData.key = attrMap[k]
}else if(k === 'key') {
nodeData.key = '`' + attrMap[k] + '`'
}else if(k === 'ref') {
nodeData.ref = attrMap[k]
}else if(k.startsWith('v-')) {
if(k.slice(2, 5) === 'on:') {
nodeData.events[k.slice(5)] = attrMap[k]
}else {
nodeData.directives[k.slice(2)] = attrMap[k]
}
}else {
nodeData.attrs[k] = attrMap[k]
}
})
nodeData.rawAttrs = attrMap
}