
正确看待 Redux 带来的复杂度问题
初用 Redux 时,我也有过一个疑惑:一个简单的数据读写操作,为什么要我写那么多样板代码?为什么这个写起来令人厌烦的架构工具却能得到如此高的流行度?随着理解的深入,我逐渐认可了 redux 的理念,本文将阐述一些我对 redux 中复杂度的看法。
注:
原始链接: https://www.404forest.com/2017/09/09/put-the-complexity-of-redux-in-perspective/
文章备份: https://github.com/jin5354/404forest/issues/63
1. 原始的数据流动方案
在模块化、组件化尚未兴起的年代,网页开发还都是多页应用,基本是一个页面配一个或多个 Javascript 逻辑文件。那时虽然不常谈起『数据流』这个概念,但是涉及到数据传递的场景,大家也都是有土方法的:
多个页面间传递数据,一般挂在 url 上传过去就行了,如: http://example.com/test?from=source&previousParam=something。
单个页面间传递数据,挂在 window 对象上互相访问:
假如我有需求,要在业务逻辑中访问到某个 jQuery 插件的内部变量,可这变量没被这个插件暴露出来,怎么办?那就在插件内部加一行代码,把这个变量挂到 window 上面。
从这里可以总结出一个规律:两个具有独立作用域的模块,想要共享内部数据该怎么办?找到一个两者均具有访问权限的第三方空间进行数据交换。
这个第三方空间,之前是 url,是 window 变量,现在则是各种数据流管理工具中的 store。
2. 自由读写的弊端
随着强调组件化的单页应用框架的兴起,页面中组件数量陡增,甚至在切换路由时页面也不会刷新,单纯是旧组件的卸载与新组件的实例化。组件之间的数据共享操作变得极为频繁,而每个组件都形成了自己的闭包,这就使得我们开始思考组件间应该如何交换数据最为优雅。
像上文所述的那样,用最简单粗暴的方法,直接在 window 变量(或者随便找个什么第三方空间)上找个地方把数据挂上去,不就可以直接读写共享数据了?是的,it works。但是当数据源增多,数据修改操作变的频繁时,你会发现,不出 bug 相安无事,一出现 bug,调试过程将是非常痛苦的一件事。你发现某个变量变为了预料之外的值,却对异常操作一无所知,你只有打无数个断点,才能确定问题出现在哪里。
举个实际的例子:(文中括号内容,为对应的 redux 中的角色)
在开发 App 内嵌网页时,需要用到 JSBridge,前端使用这个组件来唤起 App 中的功能。这是一个典型的跨部门合作情况。App 部门实现功能,并向前端部门提供 JSBridge 文档(共享数据),前端部门根据文档进行使用。
某次 App 部门修改了 JSBridge 的调用方式,修改文档时因操作失误未修改成功。之后前端部门在使用 JSBridge 时发现异常,反复核对文档、核对业务代码均未发现问题,找到 App 部门也是一脸懵逼,花费很多沟通成本才定位到问题出现在哪里。
自由读写确实能达到共享数据的目的,写起来也简单粗暴,但是其可维护性非常差,组件一多,bug 追踪成本极高。
3. redux 要解决的问题
之后,App 部门在开发内部管理系统(redux)时,将 JSBridge 纳入,修改操作一律提单子(
dispatchaction),老大审核后数据更新,单子归档(immutable),文档同步发布,并向两部门人员发送告知邮件(log middleware)。通知及时,出了问题看归档也能迅速正确分锅,两部门终于过上了幸福美满的生活(误)。
Redux 就是为了解决可维护性而出现的数据流管理工具。他就像上文提到的管理系统一样,引入了一些概念,人为的定义了数据修改的流程:dispatch action -> reduce。所有可能的数据修改手段,都使用 reduce 收束为有限的几类。想要修改数据,必须醒目的、充满『仪式感』的『提单子』——即调用 dispatch。修改数据时,不会直接修改原 store 内的数据,而是生成新的 state,并将旧 state 存档,以此来实现时间回溯功能。
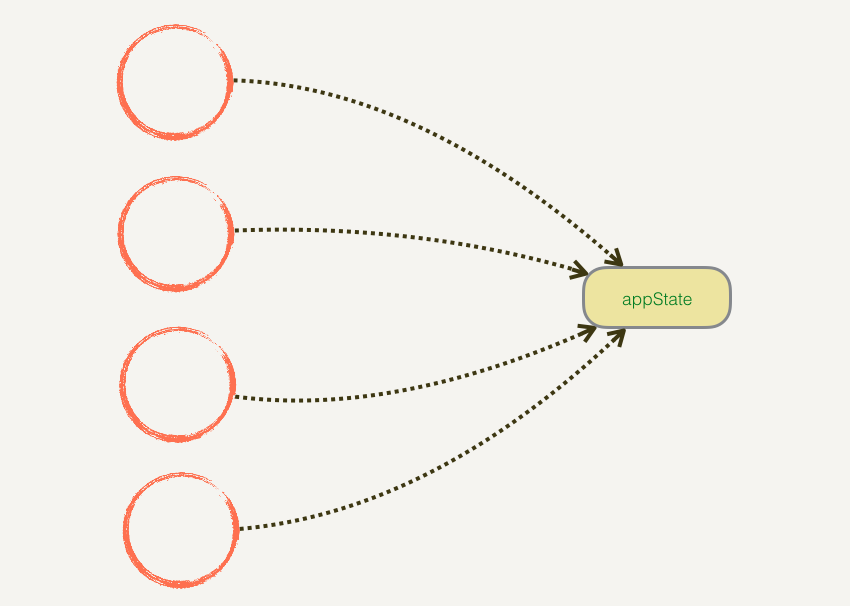
自由读写数据,简单粗暴,bug 难以追踪。[上图来自React.js 小书]
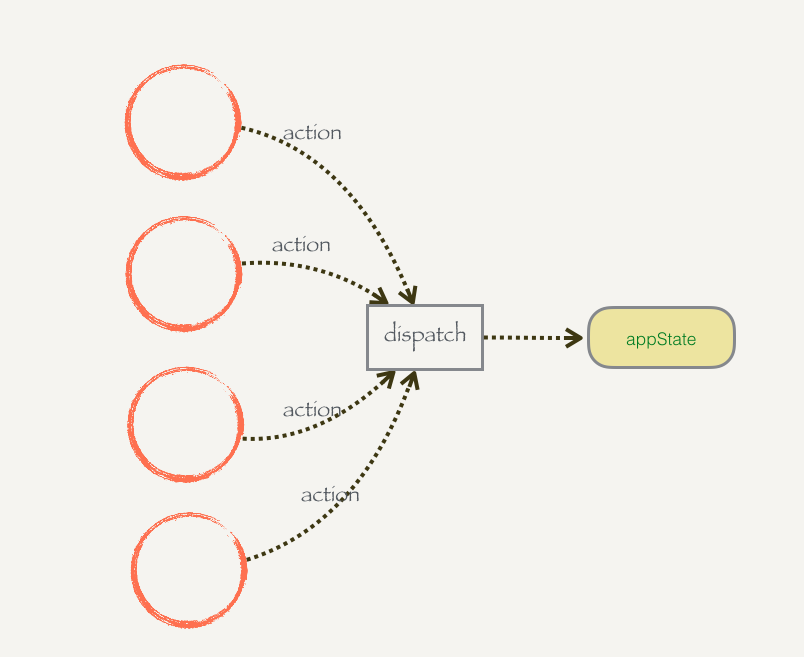
使用 redux 中的 dispatch 派发 action 执行 reduce, 对数据进行有限种类的修改,彻底阻止意外改动。([上图来自React.js 小书])
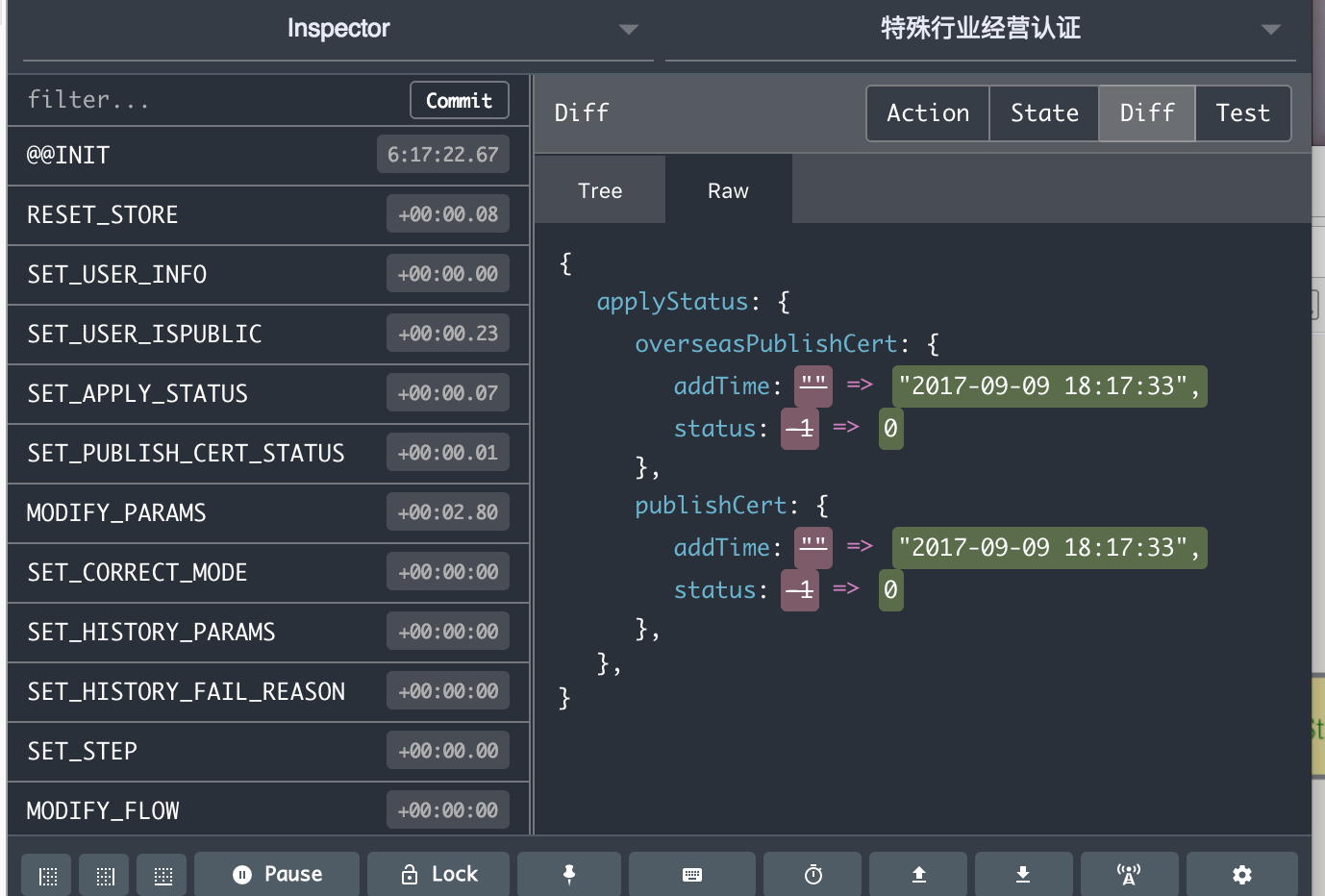
每次数据修改行为、旧 state 都留档,开发者可随时通过 devTool 查看记录,极大方便调试与维护。
redux 将自由散漫的数据修改方式进行约束,构建成了一种充满『控制欲』的、带有一点『官僚体系』作风的状态管理工具,为我们带来了 devtool 等方便的辅助工具,极大的方便了应用中的数据流管理、bug 追踪和调试。
4. 并不复杂的 redux
redux 文档中所描述的『单向数据流』、『可预测性』等术语往往令新使用者感到虚无缥缈。从上面所举例可看出,redux 的数据流管理模式其实借鉴了现代企业的数据管理哲学,可谓是站在前人的肩膀上;以现实的例子去理解 redux 中的各个环节也更加轻松。
实际上,redux 的原理极为简单,其核心只有 store(准备一个第三方空间) 和 dispatch(用修改后的老数据替换新数据) 两部分,源码不过百余行(reduce 和初始 state 由用户自己编写)。只要你能理解例子中的管理系统的运转方式,你就能明白 redux 中的部件是多么的简单而又必需,一切都是为了实现数据可控的目标。
常能听见『redux 好麻烦啊』『写 redux 重复代码太多了,不想用了』的抱怨。这种场景多出现在 redux 的初学者身上——他们在代码百余行的 demo 项目里用 redux,就如同只有 2 个人的公司还一切非要用 JIRA 管理,只会有徒增烦恼的感觉;只有在成规模的项目中,你才能体会到 redux 带来的好处。
redux 的出发点从来都不是简洁、省事儿,而是让你通过预设规则,也就是多写代码来提高应用数据流的可控性,让你在数据流越来越复杂,越来越庞大时依然能 hold 住,在出现 bug 时依然能掌控全局,快速定位问题。这是一个可控性与代码量的 trade off。 在这点上,他与单元测试很像:增强了安全感,并让日后的维护调试不再痛苦不堪。